Data Analysis involves a series of steps generally performed in pandas when it comes to python. While powerful, pandas may face performance issues with large datasets and resource-intensive operations.
DuckDB emerges as an excellent alternative. As a high-speed, user-friendly analytics database, DuckDB is transforming data processing in Python and R.
What is DuckDB?
DuckDB is a free, open-source, embedded, in-process, relational, OnLine Analytical Processing (OLAP) DataBase Management System (DBMS).
As per our title by In-Process means
DBMS features are running from within the application you’re trying to access from instead of an external process your application connects to.
Since DuckDB is an OLAP database, any data stored is organized by columns. Additionally, DuckDB is optimized to perform complex queries on data.
If you’re familiar with SQLite, the easiest way to conceptualize DuckDB is as its analytics-focused replica. This plays into why DuckDB is so popular — it leverages the simplicity of SQLite and the functionalities of Snowflake on your local computer. DuckDB fills the need for an embedded database solution for analytical processing.
Key Features of DuckDB?
1. Fast analytical queries –
DuckDB runs on a columnar-vectorized query engine, which helps to make efficient use of the CPU cache and speed up response times for analytical query workloads, and this makes DuckDB incredibly faster as compare to traditional DBMS.
2. Supports SQL and integration with other programming languages –
DuckDB enables users to run complex SQL Queries and provides APIs for Java, C, C++, and more. It’s also deeply integrated into Python and R, enabling users to conduct efficient interactive data analysis; thus, you can interact with DuckDB from your preferred programming language. There’s also access to extra SQL keywords that make SQL queries easier to write, such as EXCLUDE, REPLACE, and ALL.
3.Free & open-source –
DuckDB is open-sourced and has several active contributors, which means developments and improvements can be implemented fast. It’s also free, although it may not remain free for good.
Let’s get started with DuckDB
pip install duckdb
Working With DuckDB in Python
# read a Parquet file into a Relation duckdb.read_csv('sample_data.csv')
# read a Parquet file into a Relation
duckdb.read_parquet('example.parquet')
##Output##
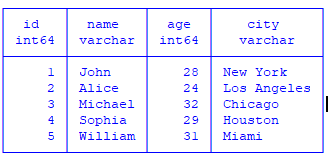
#directly querying the existing file into SQL
duckdb.sql('SELECT * FROM "C:\\Users\\Dell\\Desktop\\sample_data.csv"')
Conclusion –
DuckDB turns your laptop into a personal analytics engine , In the era of cloud computing we can definitely, scale our DuckDB with help of MotherDuck.
MotherDuck scales your laptop into the cloud with Hybrid Execution.