
If you are looking to migrate your existing on-premise Hadoop based Pysaprk jobs on GCP and don’t want to create a Dataproc cluster and run your jobs on that, here are 3 different ways you can achieve that.
Basic information of all services mentioned in this article:
Dataflow:
- Dataflow is designed for both batch and stream processing and provides a unified model for handling both types of data processing workloads. It’s ideal for data transformation, data enrichment, and real-time analytics. It is a fully managed service, automating resource provisioning, scaling, and optimisation. Users define processing logic using Dataflow’s programming model.
- Dataflow is designed for automatic scaling based on workload demands, making it well-suited for stream processing. Charges are based on the number of processing units (vCPUs and memory) used during job execution.
BigQuery:
- BigQuery is a server-less data warehouse, and stored procedures are executed within the BigQuery environment. Users don’t need to manage clusters or infrastructure. It automatically handles query execution and scaling, making it easy to handle large datasets. BigQuery Stored Procedures are used to create reusable SQL-based routines and logic within the BigQuery data warehouse. They are suitable for complex data manipulations and transformations within BigQuery itself.
- BigQuery charges are based on the amount of data processed by queries, storage, and streaming inserts. There is no separate charge for using stored procedures.
Dataform:
- Dataform is a data modelling and transformation tool that helps data engineers and analysts manage the entire data transformation life-cycle. It allows you to define and manage SQL-based transformations, version control, and orchestration of data pipelines. Dataform promotes code re-usability and collaboration among data teams by using a version-controlled, modular approach to data transformations.
- Dataform itself is free to use, but users pay for the underlying data warehouse resources (e.g., BigQuery) and storage.
In all of the below pipelines Input/raw HDFS layer is replaced by GCS buckets & final/processed HDFS layer is replaced by BigQuery tables. And, suggested orchestration service from GCP is Cloud Composer.
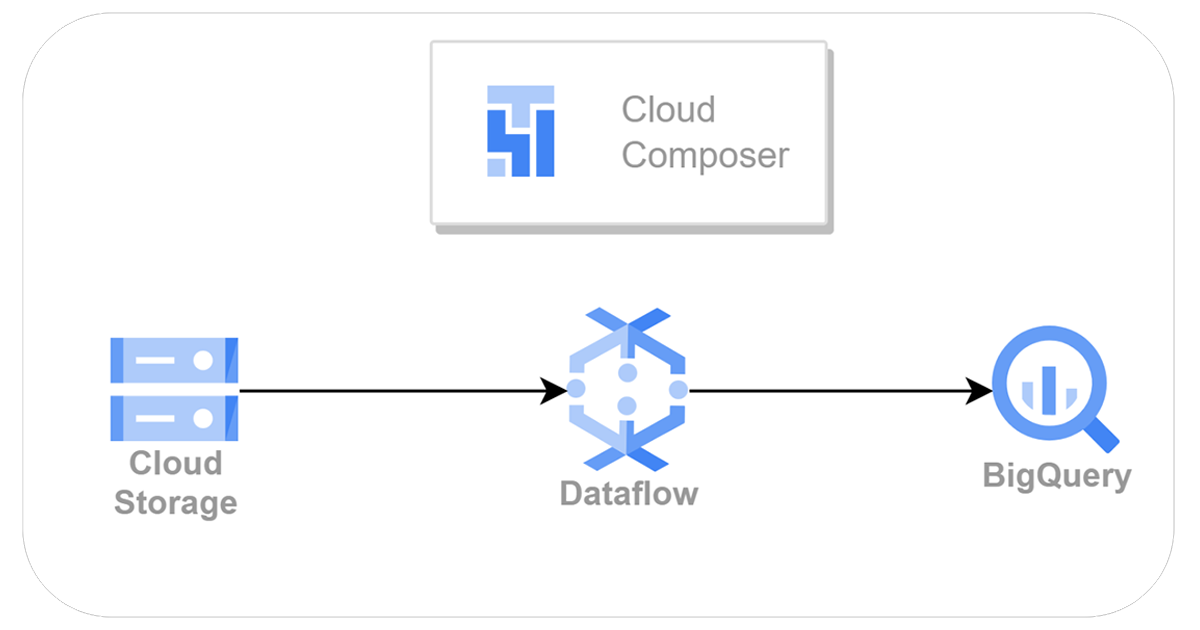
A) Raw data can reside on GCS buckets.
B) Review your existing PySpark code and identify the key data processing logic and transformations. Refactor your code to use Apache Beam, which is the programming model behind Google Cloud Dataflow. Modify your data processing logic to fit the Apache Beam model by transforming your PySpark code into Dataflow pipelines written as Python scripts.
C) Final data is stored in BigQuery tables.
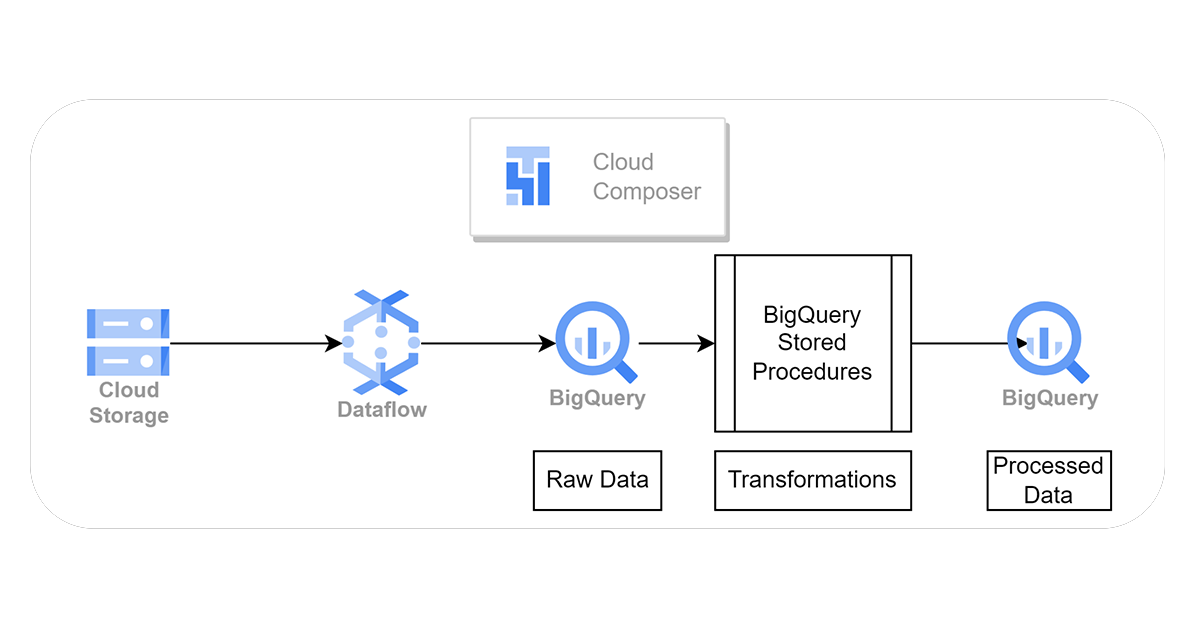
A) Raw data can reside on GCS buckets.
B) Google Cloud Dataflow jobs will read the data from buckets and write into input/raw BigQuery tables without doing any additional transformations.
C) Rewrite your data processing logic as SQL queries or stored procedures. This will involve translating your PySpark transformations into SQL operations. You can create user-defined functions (UDFs) in BigQuery if needed. Write SQL stored procedures within BigQuery that encapsulate your data processing logic. You can create and manage stored procedures using the BigQuery web console, command-line tools, or client libraries.
D) Stored procedures will store the final data is in final/processed BigQuery tables.
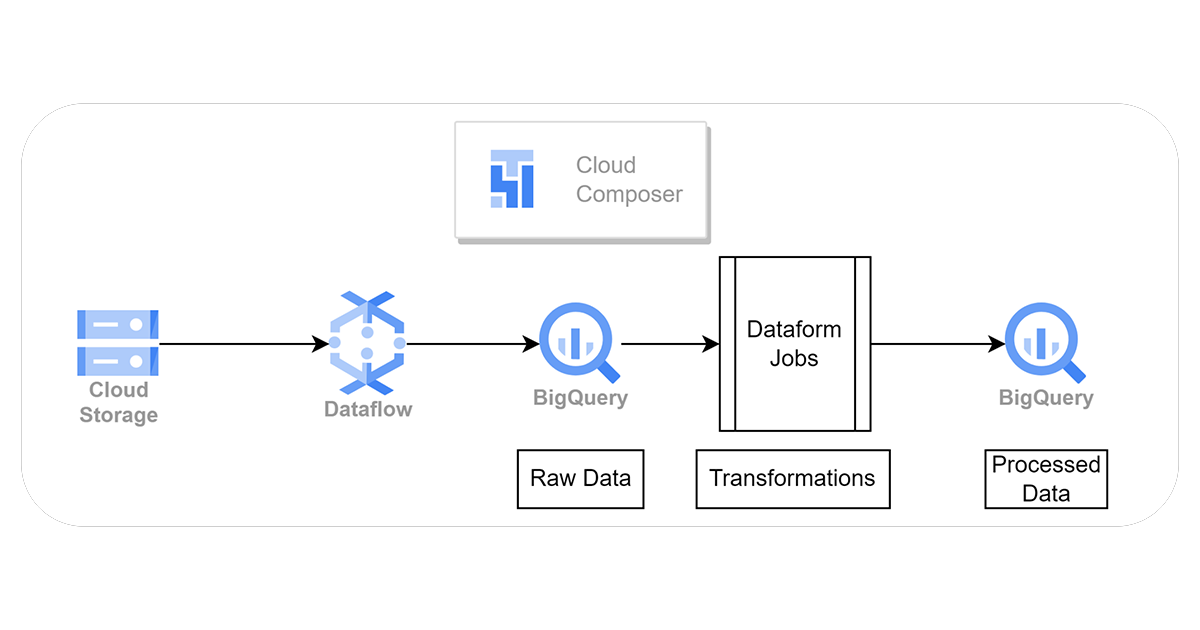
A) Raw data can reside on GCS buckets.
B) Google Cloud Dataflow jobs will read the data from buckets and write into input/raw BigQuery tables without doing any additional transformations.
C) Rewrite your data processing logic as SQL-based Dataform transformations. Dataform uses SQL-like syntax for defining transformations and models. Identify any custom functions or business logic in your PySpark code and determine how to implement them within Dataform. Define Dataform models that correspond to the tables or views in your data warehouse. These models represent the output of your data transformations.
D) Dataform jobs will store the final data is in final/processed BigQuery tables.
How to decide which Pipeline to use ?
- Developer compatibility:
One of the most important aspects. Dataflow is built on Apache Beam and custom jobs can be created in Python using Beam pipelines. Whereas BQ Stored Procs & Dataform jobs uses SQL like syntax.
In Pipeline II & III Dataflow is used only to read data from GCS backet and write to BQ raw tables. Without any actual transformations on the data. All complex transformations are done using BigQuery compute in both pipelines II & III.
But, in Pipeline I Dataflow is used to convert all Pyspark transformations using Dataflow job and write processed data in BQ tables. So, familiarity with Dataflow is a big factor during selection. - Compute:
Which compute you are open to use for complex transformations. Dataflow or BigQuery. Based on the use case performance and cost may vary for both so that is also an important selection factor. From our small experiments we found that BigQuery stored procedures and Dataform transformation jobs are executing faster compared to Dataflow transformation job.
Pyspark Functions mapping with Dataflow, BigQuery SQL & Dataflow SQLX
This is a mapping sheet that our team has created for 50+ Pysaprk transformation functions and their equivalents in Dataflow, Big Query SQL & Dataform SQLX which can help one get started converting existing Pyspark scripts to write & execute scripts using any of the above mentioned 3 pipelines.