
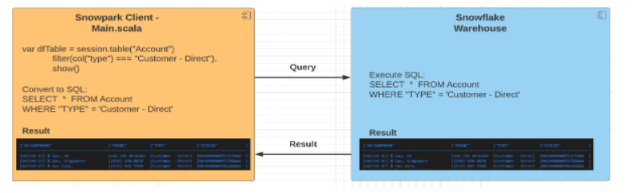
Snowpark provides a data programmability interface for Snowflake. It provides a developer experience that brings deeply integrated, Dataframe-style programming to Snowflake for the languages developers like to use, including Scala, Java, and Python.
Snowpark is a new developer library in Snowflake that provides an API to process data using programming languages like Scala (and later on Java or Python), instead of SQL.
All our data remains inside our Snowflake Data Cloud when it is processed, so indirectly it reduces the cost of moving data out of the cloud to other services. Snowpark uses its own (snowflakes) processing engine that’s why it eliminates the cost of external infrastructure like Spark infrastructure.
Basic steps/understanding required before migrating spark to snowspark
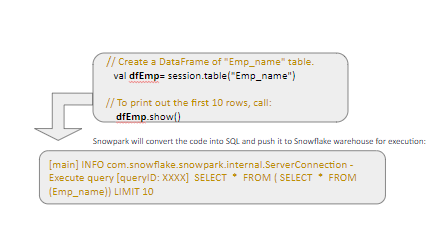
Case 1. If our Existing Job/code is Using DataFrame or Spark SQL API.
If our existing job is using SPARK SQL API/Dataframe then migration will be a copy/paste thing. We don’t need to write complex code and additional logic to migrate our existing code. In case our spark job uses a combination of dataframe and UDF then it will be a little complex to migrate our job.
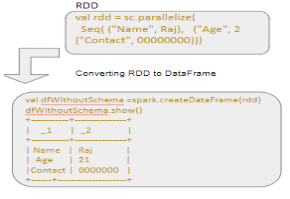
Case 2. If our Existing Job/code is using RDD
If our Spark workflow currently makes use of any UDAFs, or uses the RDD API, there will be some work in re-writing the logic to convert into the DataFrame API
Below are the factors/key points that needs to be considered while migration.
1. All the SQL function we use are available in snowpark
Example : There are some differences in a couple of the built-in SQL functions (i.e. “collect_list()” vs. “array_agg()”, as well as how some Dataframe mthods are handled. For example, in Spark, a “.pivot()” is executed against a grouped dataset, while in Snowpark the grouping is implicitly assumed based on the available columns, and is executed against the DataFrame itself.
2. Supported data types should be passed in snowpark UDF.