

The world had never imagined that one day creating images, videos, songs, books and way much more would be possible with just one line of a text.
All this is now possible with the help of the great pre-trained Generative AI models. It has now become a part of our daily life’s.
But now, imagine you have millions and billion pages of unlabelled and unknown data and want to get a summary of every topic within seconds?
How will you do it?
Spoiler alert: By using Generative AI and Vector Databases.
I’ve been engrossed in a fascinating project that integrates generative AI and vector databases that addresses a unique use case.
Let me take you through the journey…
I started by setting up a pipeline to snag daily news URLs from a news API. With a bit of web scraping magic on these URLs, I extract the actual news text. This text undergoes a transformation into vector embeddings, finding a home in a dedicated vector database. Now, the real excitement begins as I deploy another pipeline to query through the vector database. Once I’ve got this curated set, I use the help of generative AI to craft concise summaries of the news. This journey has been like connecting the dots with technology to get meaningful insights.

Let me walk you through a challenge in the industry arising from the extensive piles of hard-copy data….
In today’s digital age, we often encounter a challenge when dealing with historical and confidential data.
These crucial pieces of information are usually stored in hard copies, while some of this crucial information may exist in digital form, the sheer volume often overwhelms officials, hindering quick access. The data, despite being in digital format, lacks effective organization, making it challenging to locate specific details promptly. The abundant amount of data, coupled with inadequate labelling and categorization, creates a situation where officials must sift through extensive digital archives, including PDFs and images.
This manual search process not only consumes valuable time but also introduces the risk of overlooking pertinent information, leading to delays in critical tasks.
Complicating matters further, the sensitive nature of the data necessitates a delicate balance between accessibility and confidentiality. Officials face a dilemma: either invest considerable time in navigating through the vast digital repository or potentially compromise confidentiality by granting broader access to expedite the search process. This dilemma emphasizes the need for innovative solutions that can streamline data management, enhance accessibility, and maintain the utmost confidentiality.
Imagine people trying to find important info about a company’s data for a specific year related to something very specific and confidential; there are about millions of PDF’s that are available. The official will have to go through piles of messy files and pictures. This not only slows down decision-making but also puts sensitive information at risk.
Having spoken to individuals facing this issue, it became clear that there was a need for a streamlined solution. I have designed a POC that could efficiently handle historical and confidential data, mitigating the delays and confidentiality concerns.
My experience with vector databases and GenAI has not only enriched my understanding but has also inspired a practical solution to streamline information retrieval and summarization.
I’ve devised a “POC” that minimizes the need for labelling each piece of data. Instead, it revolves around efficiently storing information extracted from PDFs to facilitate quick retrieval and automatic summarization. The core of this innovation lies in an automated pipeline that not only stores PDF data in a vector database but also leverages the power of GenAI for advanced summarization. By utilizing vector representations (embeddings), the solution ensures swift and effective retrieval of required data, eliminating the need for manual perusal.
Implementing this solution involved setting up a continuous, real-time updating pipeline for the vector database. This setup allows us to request information from the system whenever needed. To bring this system to life, I choose the Google Cloud Platform and its robust services due to their strong and reliable capabilities.
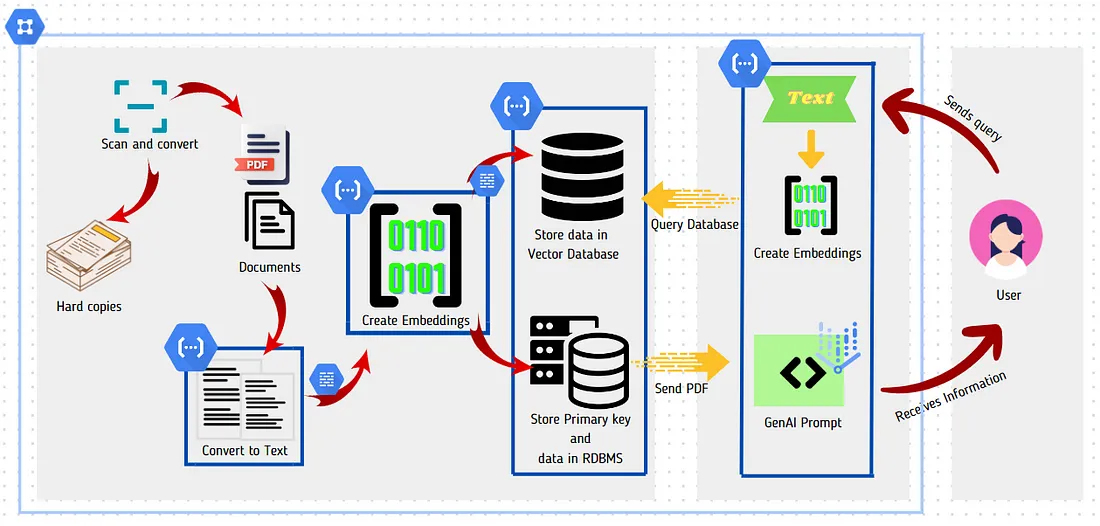
Key Components:
- Vector Databases: Acting as the backbone of the solution, these dynamic databases eliminate the need for extensive manual labelling. Their intelligence lies in efficiently storing and retrieving information from PDFs, simplifying the otherwise intricate process.
- GenAI: A testament to the power of artificial intelligence, GenAI infuses cognitive capabilities into the system. It automates summarization and enhances contextual understanding, reducing the time required for information retrieval while maintaining a nuanced understanding of the stored data.
- Other cloud services: The utilization of GCP’s cloud functions for compute services and the cloud task manager brings a level of sophistication that ensures seamless scalability. There are other choices too, like Cloud Run, where you can easily create and use containers or you can go with Compute Engine and Google Kubernetes for your pipeline. It’s all about having options to fit what works best for you. For data security, you can also create services under the VPN.
Overview of the pipeline:
Step1 :The first step is to Scan and convert hard copies into PDFs or images.
Next,
Step 2 :Create Text Extraction Cloud Function (HTTP Trigger):
- Takes PDF input as Base64 stream.
- Converts PDF content to text.
Step 3 :Create Text to Embeddings Cloud Function (HTTP Trigger):
- Second cloud function triggered by GCP Cloud Task.
- Accepts text payload.
- Converts text into embeddings using a pre-trained model.
Step 4 :Create updating index Cloud function (HTTP Trigger):
- Third cloud function triggered by GCP Cloud Task.
- Accepts text payload.
- Generates a unique ID.
- Sends Embeddings and ID to vector search database.
- Sends PDF name, location and ID to an RDBMS for storage.
Step 5 :Lastly create Query vector database for summarization Cloud function (HTTP Trigger):
New function accepts query text as a payload from the user.
- Converts text into embeddings.
- Uses vector search to find the nearest neighbour, obtaining its ID.
- Queries RDBMS using the obtained ID.
- Retrieves PDF name and location.
- Fetches the identified PDF.
- Sends PDF to GenAI for summarization.
- The response is the summary is reverted as the output.
Let’s break down the intricacies of this pipeline to better grasp its transformative power.
Data Source:
The data can come from either hard copies or PDFs. To make this information usable, it needs to be converted into text. I have personally explored various Python libraries which gives good results when converting to pdf to text, such as
- pydf2
- pytesseract
- mymupdf
- pdfminer.six
- easyocr
- pyocr
- GCP’s DocumentAI.
However, it’s worth noting that the usage of GCP’s DocumentAI custom model can be relatively costly. It’s important to recognize that these libraries work best with high-quality images or PDFs for the most effective results.
Text Embeddings:
Let’s first understand what Embeddings are!
In simple terms, embeddings in machine learning are a way to represent things like words, phrases, or documents as numbers. Imagine each word or piece of text is assigned a unique set of numbers, kind of like a secret code. The cool part is that similar words or meanings end up having similar codes.
Imagine you have a database that stores information about various things, like documents or sentences. Now, an embedding in this database is like a special code or signature assigned to each piece of information.
This code is a set of numbers that somehow captures the essence or meaning of the information. Similar pieces of information end up having similar codes. So, when you want to find something similar in the database, you look at these codes rather than the actual content.
In a nutshell, embeddings in a vector database help organize and find similar things by assigning them special numeric codes, making it easier for a computer to quickly understand and retrieve relevant information.

Coming back to the pipeline flow, after converting the text, the next step is to create embeddings using the gcp textembedding-gecko model or other available versions. Text embeddings essentially turn the text into numerical representations, represented as arrays of floating-point numbers. This allows for comparing the similarity between different pieces of text or the objects represented by the text. It’s important to consider limitations when working with embeddings. For each request, there’s a restriction of five input texts, and each input text has a token limit of 3,072. Inputs longer than this length are silently truncated. However, it’s possible to disable silent truncation by setting autoTruncate to false. It is also important to select the right region when using the textembedding-gecko model for creating embeddings because the model is not available in all the regions and one can encounter model not found error.
I am adding a small code snippet provided by GCP for creating embeddings, which takes 5 input text for each request.
import time
from vertexai.language_models import TextEmbeddingModel
import vertexai
vertexai.init(project=, location="us-central1")
# get embeddings for a list of texts
BATCH_SIZE = 5
def get_embedding(texts):
embs = []
for i in range(0, len(texts), BATCH_SIZE):
time.sleep(1) # to avoid the quota error
result = model.get_embeddings(texts[i:i + BATCH_SIZE])
embs = embs + [e.values for e in result]
return embs
Updating GCP’s Vector Search Index:
Before understanding about updating index let’s look what vector search database is?
Vector database is a type of database that is optimized for storing and efficiently querying vector representations of data. In this context, a vector is a mathematical representation of an object or document that captures its essential features in a numerical form.
Traditional databases are designed for structured data, such as text, numbers, and dates. However, they may not be well-suited for handling the complexity and nuances of unstructured data, such as images, audio, or natural language text. Vector databases address this limitation by representing data as vectors and employing algorithms that can measure the similarity between vectors.
Key features of vector databases include:
- Vector Representation: Data, such as text documents or images, is converted into numerical vectors. Each element in the vector corresponds to a specific feature of the data.
- Similarity Search: Vector databases excel at similarity searches. They can quickly identify items that are similar or closely related to a given query vector. This is particularly useful in applications like image search, recommendation systems, and natural language processing.
- Efficient Retrieval: Vector databases use advanced indexing and search algorithms to enable fast and efficient retrieval of data based on similarity metrics.
- Nearest Neighbour Search: A common operation in vector databases is the retrieval of the nearest neighbours to a given vector. This is useful in scenarios where finding similar items is a primary objective.
- Scalability: Vector databases are designed to handle large-scale datasets efficiently, making them suitable for applications with extensive and growing data repositories.
Now, what is an index?
According to GCP’s vector search Index Is a collection of vectors deployed together for similarity search. Vectors can be added to or removed from an index. Similarity search queries are issued to a specific index and search the vectors in that index.
Let’s come back to updating the index in database. The created embeddings are then sent to update the index of GCP’s vector search. It’s essential to have a pre-deployed index on an endpoint for this process. GCP’s vector search supports both streaming and batch updates. Streaming updates take seconds to update the database, while batch updates can take longer, potentially hours. I am attaching the links of GCP git repository where you can find python code for batch and streaming updates. Remember, vector search only stores IDs and embeddings in its database. So, when queried we get the id of the corresponding nearest neighbour. The number of nearest neighbours can be managed by changing the number of nearest neighbours we want the database to retrieve.
Updating a RDBS:
You can pick any Relational Database System (RDBS) to store the data of IDs and the PDF name and location. So, when we get an ID from the vector search, we can ask the RDBS to give us the PDF. Then we can convert it to text and send it to the Gen AI model for summarization.
Querying the Database:
Once the vector search index is updated, the database becomes a powerful tool for querying and fetching information. This enables efficient retrieval of details from PDFs based on the numerical representations created earlier.
Gen AI Summarization:
The final step involves sending the retrieved PDF information to Gen AI for summarization. This step adds an extra layer of intelligence to the system, facilitating quick access to summarized information. I am attaching a prompt that can help to get the summary of the pdfs that we want.
Additionally, I’ll be dedicating a future article to share insights and experiences with crafting effective prompts for Gen AI. Stay tuned for a deep dive into the art of leveraging prompts to get the most out of Gen AI’s capabilities.
I hope you find this article helpful. If you have any specific questions or if there’s something more you’d like to explore, feel free to drop your queries in the comments. I’m also considering creating a small code repository with handy snippets related to this process. If you’re interested, I can share the repository to facilitate smoother implementation. Your feedback and collaboration are highly valued!
“Summarize the key insights from the provided text below and present the information in a concise format. Highlight important details and main findings.
Input: <Enter your text here>.
Output:”